
The shift toward system design
The coding interview process for FAANG companies – Facebook (Meta), Apple, Amazon, Netflix, and Google – is evolving. While proficiency in data structures and algorithms remains important, the emphasis is undeniably shifting towards system design. This isn’t a new trend, but its acceleration is clear. Companies are increasingly looking for engineers who can think beyond individual code snippets and grasp the bigger picture of building and scaling complex systems.
A few years ago, you could often get by with strong algorithmic skills. Now, interviewers want to see how you approach open-ended problems, handle ambiguity, and make architectural decisions. This change reflects the realities of working at these companies, where engineers are frequently tasked with designing and maintaining systems that serve millions or even billions of users. The rise of distributed systems and cloud computing has only amplified this need.
The core concepts of system design remain steady, but FAANG interviewers now expect deeper fluency in applying them to realistic scenarios. We'll look at the essential building blocks and how to navigate the most common architectural questions.
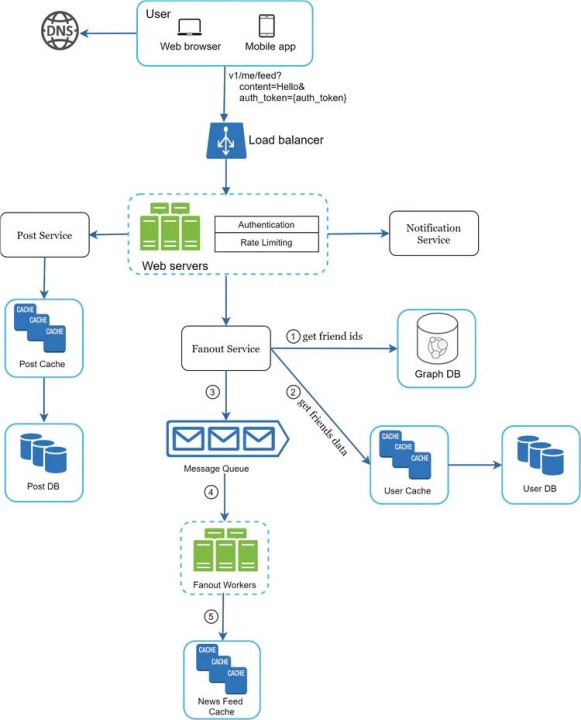
Fundamental building blocks
Success in these interviews depends on how you weigh trade-offs between different architectural components.
Load balancing distributes traffic across multiple servers to prevent overload. Options range from simple round-robin to more sophisticated algorithms based on server capacity or latency. Caching stores frequently accessed data closer to the user, reducing latency and database load. Consider the eviction policies – Least Recently Used (LRU), Least Frequently Used (LFU) – and their implications.
Databases are a cornerstone of most systems. SQL databases (like PostgreSQL or MySQL) offer strong consistency and relational integrity, while NoSQL databases (like MongoDB or Cassandra) prioritize scalability and flexibility. Message queues (like Kafka or RabbitMQ) enable asynchronous communication between services, improving resilience and decoupling. Finally, the CAP theorem – Consistency, Availability, Partition Tolerance – highlights the inherent trade-offs in distributed systems. You can’t have all three simultaneously; you must choose which to prioritize.
How to design a rate limiter
Let's walk through a detailed solution for a common system design question: designing a rate limiter. A rate limiter controls the rate at which users can access an API or resource, preventing abuse and ensuring fair usage. Several algorithms can be used, each with its own strengths and weaknesses. The token bucket algorithm is a popular choice. Imagine a bucket filled with tokens; each request consumes a token. Tokens are replenished at a fixed rate. If the bucket is empty, the request is rejected.
Another option is the leaky bucket algorithm. Requests enter the bucket, and are processed at a fixed rate. If the bucket overflows, requests are dropped. The fixed window counter algorithm divides time into fixed-size windows and counts requests within each window. This is simpler to implement but can lead to bursts at the beginning of each window. Choosing the right algorithm depends on the specific requirements. Do you need to handle bursts? What is the desired level of accuracy?
For scalability, a distributed rate limiter is essential. A central database can become a bottleneck. Instead, we can use a consistent hashing algorithm to distribute requests across multiple rate limiter servers. We also need to consider failure scenarios. What happens if a rate limiter server goes down? Redundancy and failover mechanisms are crucial. Redis is a good choice for storing the rate limit counters due to its speed and support for atomic operations. Concurrency is also a concern; we need to ensure that counters are updated atomically to avoid race conditions.
System Design Question Types
- URL Shortener - Design a system to shorten long URLs into shorter, more manageable links. Core challenges involve hash function design, collision handling, and scalability to handle a massive number of requests.
- Rate Limiter - Implement a system to control the rate of incoming requests to prevent abuse and ensure service availability. Challenges include choosing the right algorithm (token bucket, leaky bucket, fixed window counter) and distributed rate limiting.
- Web Crawler - Design a system to crawl and index web pages. This involves handling politeness (robots.txt), avoiding cycles, and efficient data storage. Consider the challenges of parallelization and scale.
- Notification System - Build a system to deliver notifications to users via various channels (push, email, SMS). Key challenges include reliability, scalability, and handling different notification types.
- Chat System - Design a real-time chat application. Focus on handling concurrent connections, message delivery guarantees, and presence/online status. Considerations include WebSocket usage and message queuing.
- Distributed Queue - Design a reliable message queue. Challenges include message persistence, fault tolerance, and ensuring messages are processed exactly once. Consider using technologies like Apache Kafka or RabbitMQ as inspiration.
- Search Autocomplete - Implement a feature that suggests search queries as the user types. This requires efficient data structures (like Tries) and algorithms for ranking suggestions. Focus on low latency.
Scaling Strategies: Beyond the Single Server
No system can remain on a single server forever. As traffic grows, you’ll need to scale your system. There are two primary ways to do this: vertically and horizontally. Vertical scaling involves increasing the resources of a single server (CPU, RAM, storage). This is simpler but has limitations. Eventually, you’ll hit a hardware ceiling.
Horizontal scaling involves adding more servers to the system. This is more complex but offers greater scalability. Sharding divides the data across multiple databases, allowing you to distribute the load. Consistent hashing ensures that data is distributed evenly and minimizes disruption when servers are added or removed. Database replication creates multiple copies of the data, improving read performance and providing redundancy.
Microservices architecture breaks down the application into smaller, independent services. This allows you to scale individual services independently and improves fault isolation. However, it also introduces complexity in terms of communication and coordination. The choice of scaling strategy depends on the specific requirements of the system. There's no one-size-fits-all solution.
SQL vs. NoSQL trade-offs
The choice between SQL and NoSQL is less binary than it used to be. SQL databases like PostgreSQL are still the standard for financial systems where ACID compliance is non-negotiable.
NoSQL databases offer greater scalability and flexibility, making them well-suited for applications with high read/write loads and evolving data models. MongoDB, a document-oriented database, is widely used for content management and personalization. Cassandra, a wide-column store, excels at handling massive datasets. However, NoSQL databases often sacrifice strong consistency for availability and partition tolerance.
The trend is towards polyglot persistence – using the right database for the right job. A modern application might use a SQL database for core transactional data and a NoSQL database for caching or storing session data. Understanding the strengths and weaknesses of each type of database is crucial for making informed decisions. Don't fall into the trap of choosing one over the other; consider the specific needs of your application.
Scaling Strategy Comparison for System Design Interviews
| Strategy | Complexity | Cost | Consistency | Availability |
|---|---|---|---|---|
| Sharding | Moderate | Moderate | Eventual | High |
| Replication | Low to Moderate | Moderate | Strong (with primary/secondary) | Very High |
| Microservices | High | High | Eventual (typically) | High |
| Caching | Low to Moderate | Low to Moderate | Eventual | High |
| Load Balancing | Low | Low | N/A - Improves existing consistency | High |
| Database Partitioning | Moderate | Moderate | Strong within partition | High |
| Content Delivery Network (CDN) | Moderate | Moderate | Eventual | Very High |
Illustrative comparison based on the article research brief. Verify current pricing, limits, and product details in the official docs before relying on it.
Resources & Further Learning
There are numerous resources available to help you prepare for system design interviews. Grokking the System Design Interview is a popular course that provides a structured approach to learning the core concepts. The System Design Primer () is a comprehensive open-source resource.
Codecademy offers courses on system design and related topics, providing hands-on coding exercises. freeCodeCamp has a wealth of free resources, including coding challenges and tutorials. Reading case studies of real-world systems (like Netflix, Uber, or Twitter) can provide valuable insights.
Focus on resources that emphasize practical application and real-world examples. Don't just memorize definitions; strive to understand the underlying principles and trade-offs. Building small projects and experimenting with different technologies will also help solidify your understanding.



No comments yet. Be the first to share your thoughts!