
The system design shift
FAANG+ interviews have moved past simple algorithm drills. While you still need to know your data structures, the real test now is system design. I've seen that companies care less about textbook answers and more about how you weigh trade-offs when building something that actually has to run at scale.
The shift reflects how companies build software. They aren’t looking for isolated coders, but engineers who can design, scale, and maintain complex systems. Expect questions that require you to architect things from scratch, or improve existing designs. Knowing Big O notation is insufficient; you need to understand how design choices impact performance, reliability, and cost.
Preparing for 2026 requires a proactive approach. The interview bar will continue to rise. Memorizing designs won’t cut it. You need to understand why certain architectural patterns are chosen over others and be able to articulate those reasons clearly. Understanding the underlying principles is vital, and the ability to communicate your thought process is paramount. This is about demonstrating engineering maturity, not just technical knowledge.
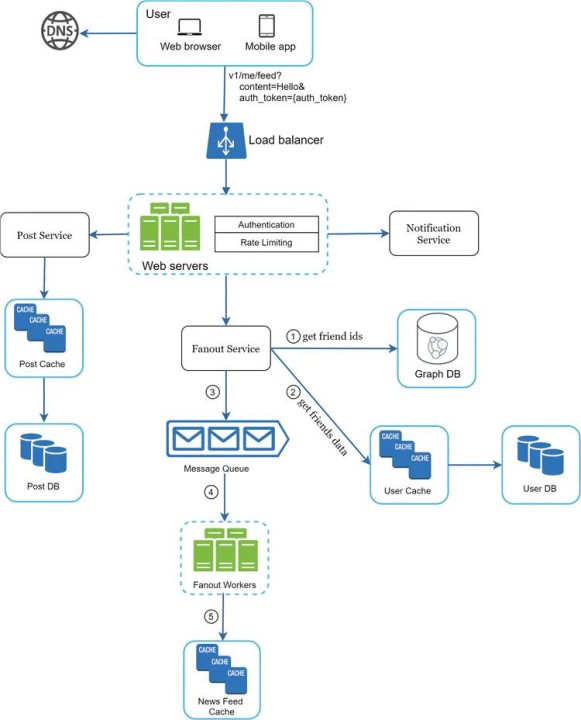
Scalability and reliability
Scalability and reliability are the cornerstones of modern system design. Scalability refers to a system’s ability to handle increasing load. This can be achieved through vertical scaling – adding more resources (CPU, RAM) to a single machine – or horizontal scaling – distributing the load across multiple machines. Horizontal scaling is generally preferred for its cost-effectiveness and fault tolerance.
Load balancing is critical for distributing traffic efficiently. Common strategies include round robin, which cycles through servers; least connections, which sends requests to the server with the fewest active connections; and consistent hashing, which maps requests to servers based on a hash function, minimizing cache misses when servers are added or removed. Redundancy is equally important. Duplicating critical components ensures that the system can continue functioning even if some components fail.
The CAP theorem is the standard way to think about these trade-offs. You generally have to pick between consistency and availability when a network partition happens. Twitter is a classic example of choosing availability—it's fine if a tweet takes an extra second to show up as long as the site doesn't go down.
Failure modes are inevitable. Designing for them means anticipating potential points of failure – network outages, database corruption, server crashes – and implementing mechanisms to mitigate their impact. This includes techniques like circuit breakers, retries, and graceful degradation. A robust system isn’t one that never fails, but one that fails gracefully and recovers quickly.
- Horizontal scaling involves adding more machines to share the load, which is usually better for fault tolerance than just buying a bigger server.
- Vertical Scaling: Adding more resources to a single machine.
- Load Balancing: Distributing traffic efficiently.
- Redundancy: Duplicating critical components.
Moving beyond relational databases
Relational databases (PostgreSQL, MySQL) have long been the workhorses of many applications. They offer strong consistency and ACID (Atomicity, Consistency, Isolation, Durability) properties, making them ideal for applications where data integrity is paramount. However, they can struggle to scale horizontally and may not be the best choice for all use cases.
NoSQL databases have emerged as powerful alternatives. MongoDB, a document database, is well-suited for applications with flexible schemas and high write loads. Cassandra, a wide-column store, excels at handling massive amounts of data and offers high availability. Redis, a key-value store, provides exceptional performance for caching and session management.
Your database choice comes down to your data's shape. If you need strict ACID compliance for financial transactions, stick with Postgres. If you're dumping massive amounts of unstructured telemetry data, Cassandra or MongoDB makes more sense.
Database sharding – partitioning data across multiple servers – is a common technique for scaling relational databases. Replication – creating multiple copies of the data – improves availability and read performance. Understanding these techniques and their trade-offs is essential for designing scalable and reliable systems.
- PostgreSQL/MySQL: Strong consistency, ACID properties.
- MongoDB: Flexible schemas, high write loads.
- Cassandra: Massive data, high availability.
- Redis works best as a lightning-fast layer for session management or temporary caches.
Database Comparison for System Design Interviews
| Database Type | Data Model Flexibility | Scalability Characteristics | Consistency Model | Typical Use Cases |
|---|---|---|---|---|
| Relational Databases (e.g., PostgreSQL, MySQL) | Highly structured; schema enforcement. Modifications can be complex. | Vertical scaling is common; horizontal scaling achievable with techniques like sharding, but adds complexity. | ACID (Atomicity, Consistency, Isolation, Durability) guarantees strong consistency. | Financial transactions, inventory management, systems requiring strict data integrity. |
| Document Databases (e.g., MongoDB, Couchbase) | Semi-structured; schema-less or schema-on-read. Allows for flexible data representation. | Designed for horizontal scalability through sharding and replication. | Eventual consistency is typical, though configurable options for stronger consistency exist. | Content management systems, catalogs, user profiles, applications with evolving data structures. |
| Key-Value Stores (e.g., Redis, DynamoDB) | Simple; data is stored as key-value pairs. Limited query capabilities. | Highly scalable horizontally; often distributed architectures. | Typically offer eventual consistency, prioritizing availability and partition tolerance. | Caching, session management, storing user preferences, real-time analytics. |
| Graph Databases (e.g., Neo4j, Amazon Neptune) | Designed for relationships; data is stored as nodes and edges. Excellent for complex relationships. | Scalability can be challenging, particularly for deeply connected graphs; distributed graph databases are emerging. | Consistency models vary; often prioritize availability and performance over strict ACID guarantees. | Social networks, recommendation engines, fraud detection, knowledge graphs. |
| Wide-Column Stores (e.g., Cassandra, HBase) | Flexible schema; columns can be added dynamically. Optimized for read/write performance at scale. | Highly scalable horizontally; designed for distributed environments. | Tunable consistency; allows trade-offs between consistency and availability. | Time-series data, logging, sensor data, applications requiring high write throughput. |
Illustrative comparison based on the article research brief. Verify current pricing, limits, and product details in the official docs before relying on it.
Caching Strategies: Speeding Things Up
Caching is a fundamental optimization technique for improving system performance. By storing frequently accessed data in a faster medium, caching reduces latency and offloads load from the primary data source. Caching layers exist at multiple levels: browser caching, CDN caching, and server-side caching.
Server-side caching often utilizes technologies like Redis and Memcached. Redis provides more advanced features, such as data structures and persistence, while Memcached is simpler and generally faster for basic key-value caching. Choosing the right caching technology depends on your application’s needs.
Cache invalidation is a complex problem. TTL (Time-To-Live) is a simple strategy, but it can lead to stale data. Write-through caching updates the cache and the data source simultaneously, ensuring consistency but increasing latency. Write-back caching updates the cache first and then asynchronously updates the data source, improving performance but risking data loss if the cache fails.
Distributed caching – using multiple cache servers – improves scalability and availability. However, it introduces challenges like cache consistency and data synchronization. Understanding these trade-offs and choosing the appropriate caching strategy is crucial for optimizing performance.
Message Queues & Asynchronous Processing
Message queues (Kafka, RabbitMQ, SQS) are essential for decoupling services and enabling asynchronous processing. Instead of directly invoking a service, a message is placed on a queue, and the service consumes it when it’s ready. This improves resilience and allows services to scale independently.
Use cases for message queues include handling background jobs (e.g., sending emails, processing images), building event-driven architectures (e.g., responding to user actions), and creating resilient systems that can handle failures gracefully. If one service is unavailable, messages will queue up and be processed when it recovers.
Key considerations include message durability (ensuring messages are not lost), message ordering (preserving the order of messages), and handling message failures (e.g., retries, dead-letter queues). Kafka is often used for high-throughput, durable message streaming, while RabbitMQ is more versatile and supports complex routing.
Microservices architectures benefit greatly from message queues. They allow services to communicate asynchronously, reducing dependencies and improving scalability. However, they also introduce complexity in terms of monitoring, tracing, and managing distributed transactions.
API Design & Rate Limiting
Designing robust and scalable APIs is critical for any modern application. RESTful principles – using standard HTTP methods (GET, POST, PUT, DELETE) and resource-based URLs – promote consistency and interoperability. API versioning (e.g., /v1/, /v2/) allows you to introduce changes without breaking existing clients.
Authentication and authorization mechanisms – such as OAuth 2.0 and JWT (JSON Web Tokens) – secure your APIs and control access to resources. Rate limiting protects against abuse and ensures service availability. Token bucket and leaky bucket algorithms are common rate limiting strategies.
API gateways – like Kong or Apigee – provide a centralized point of control for managing API traffic, security, and monitoring. They can handle authentication, authorization, rate limiting, and request transformation. They also provide valuable insights into API usage.
Idempotency – ensuring that an operation can be safely repeated without causing unintended side effects – is crucial for handling retries in distributed systems. Implementing idempotency keys allows you to track which requests have already been processed.
Common System Design Interview Questions
Expect to be asked to design systems from scratch or improve existing ones. Here are a few common questions: Design a URL shortener: Focus on generating unique short URLs, handling high traffic, and storing URL mappings. Design Twitter: Discuss scaling the timeline, handling tweets, and managing follower relationships. Design a rate limiter: Implement algorithms to prevent abuse and ensure fair usage.
For each question, start by clarifying the requirements and constraints. Then, propose a high-level design, outlining the key components and their interactions. Discuss the trade-offs involved in your design choices. Don’t get bogged down in implementation details; focus on the overall architecture.
Interviewers are less interested in the "correct" answer and more interested in your thought process. Explain why you're making certain decisions, and be prepared to justify your choices. Be open to feedback and willing to iterate on your design. A good candidate can articulate trade-offs and explain how they would adapt to changing requirements.
Recent feedback from candidates at FAANG+ companies indicates interviewers are increasingly focused on practical considerations like operational overhead and cost optimization. They want to see that you can think beyond the theoretical and consider the real-world implications of your designs. They also value clear communication and the ability to collaborate effectively.
Which system design question do you find most challenging during coding interview preparation?
System design interviews remain one of the biggest hurdles for candidates targeting FAANG+ companies. We want to know where you struggle the most so we can tailor our upcoming tutorials accordingly. Vote below and share your experience in the comments.



No comments yet. Be the first to share your thoughts!